
I want to scan a bunch of typewritten pages. I have an HP OfficeJet Pro 8600, which has a sheet feeeder on the scanner (that is why I got it). It works well with xsane. So … run xsane.
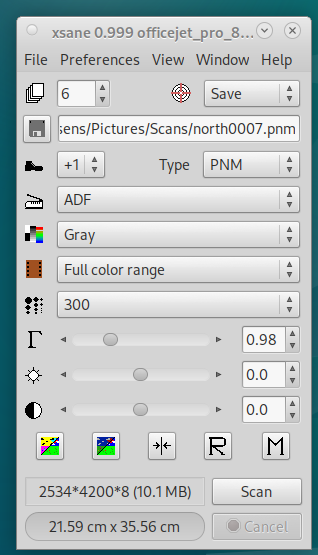 Choose ADF instead of Flatbed (ADF = automatic document feeder).
Choose ADF instead of Flatbed (ADF = automatic document feeder).- Choose PNM (Tesseract reads these).
- Choose 300 DPI.
- Set the correct number of pages (this is important — leave this as ‘1’ and it will scan all pages but you’ll only get a file for the first one).
- Where the boot is, set the increment in file names (usually this will be 1, but if you are scanning fronts then backs, you can set this to 2, then start at 1 for the fronts and 2 for the backs, and interleave them).
- Select Gray (grey), Full colour range.
- Hit ‘Scan’.

This will/should result in a whole series of PNM files with graduated names. Something like:
north0001.pnm
north0002.pnm
north0003.pnm
Here’s a bit of one.
![]() Then we can try to scan one of them:
Then we can try to scan one of them:
tesseract --dpi 300 north0001.pnm n1 vim n1.txt
OK, works, so automate:
for f in *.pnm ; do tesseract --dpi 300 $f $f ; echo $f done! ; done Detected 155 diacritics north0001.pnm done! north0002.pnm done! Error in boxClipToRectangle: box outside rectangle Error in pixScanForForeground: invalid box north0003.pnm done!
Lots of diacritics usually means dirty paper. boxClip stuff, I don’t know, but does not seem to affect the results.
Assuming your files are in the right order, you can just cat them all together and happily edit.
cat north*.txt > North.txt vim North.txt
Then edit as normal.
This works really well if you have a decent ribbon and clean paper. For example, the snippet above came out as:
Just because you have to try, thought Jake, doesn’t mean you have to Care.
So you can see that despite some grottiness on the paper and a general greyness to the scan, and the fact that this is a typical typewriter font, not a font designed for OCR, the only error is that Tesseract has put a capital ‘C’ on ‘care’. That’s pretty good!
I have tried a few OCR tools, and these days I go straight to Tesseract.
